The Geography of GPU Pricing: What A100 vs H100 Tells Us About the Global Compute Market
Global location impacts A100 and H100 GPU rental prices with key insights into regional cost gaps.

In the world of artificial intelligence, discussions about GPUs often center on architecture, performance benchmarks, and model throughput. But there’s a critical variable that rarely gets the attention it deserves: geography.
The global distribution of NVIDIA’s A100 and H100 GPUs has exposed significant price disparities across different regions, driven not by technology, but by location, infrastructure, and supply chain dynamics. At Silicon Data, we analyzed GPU rental prices across hundreds of providers globally to map these trends. What we found was more than a few isolated price differences — we uncovered a structural imbalance in the global compute market.
This article explores how location directly impacts the price of compute, what’s behind these geographic pricing gaps, and what it means for organizations trying to build, train, and deploy AI models efficiently in 2026 and beyond.
Why Geography Matters More Than Ever in Compute Pricing
In an ideal world, GPUs would be priced according to their specifications — the amount of memory, number of cores, and their architecture. But in the real world, a single A100 or H100 can cost 5–6 times more per hour depending on where it’s located.
It’s not about the GPU — it’s about where the GPU is sitting, who owns it, and how easily it can be accessed.
Just as oil, lithium, or real estate varies by location, compute power is now a geographically sensitive commodity. It’s subject to supply chains, trade restrictions, infrastructure readiness, and demand concentration.
In today’s AI economy, location is becoming one of the most powerful price drivers in compute infrastructure.
Global Pricing Breakdown: A100 vs. H100 in 2025
Let’s begin by looking at how A100 and H100 rental prices vary across the globe. The following charts, derived from a Silicon Data survey of providers worldwide, paint a vivid picture of this disparity.
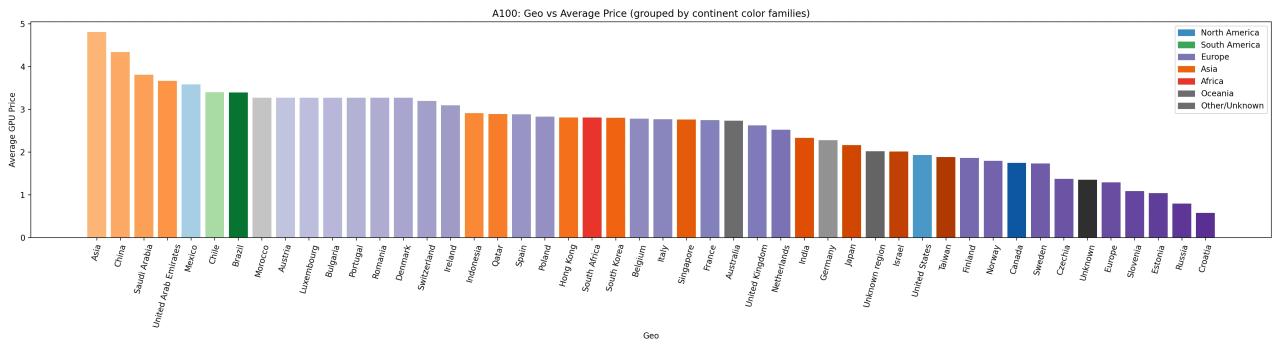
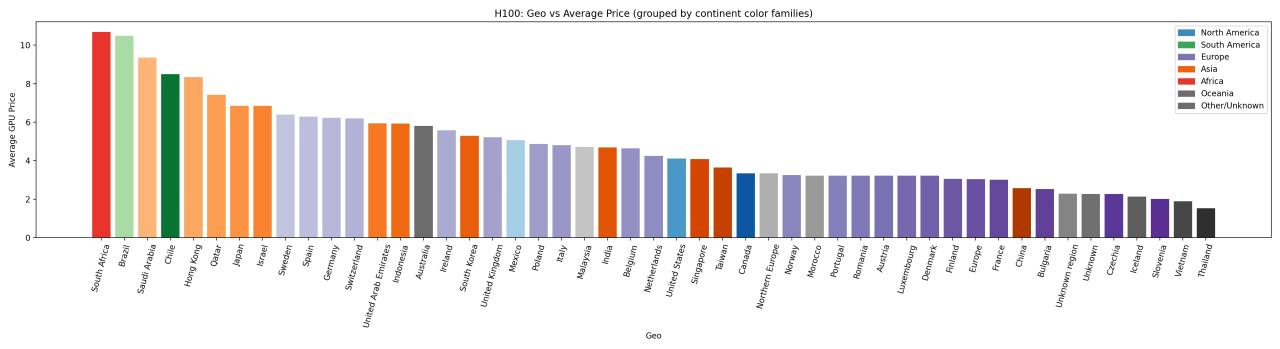
A100 Pricing: Widely Available, Still Regionally Uneven
The NVIDIA A100, released in 2020, is now considered a mature product. It’s widely available across major cloud platforms, regional hosting providers, and GPU marketplaces. But even with commoditization, prices remain highly sensitive to geography.
- North AmericaNorth America offers some of the lowest A100 prices globally, ranging from $1.75 to $3.58/hr, US and Canada specifically cluster tightly at ~$1.75–$1.93/hr,Mexico is higher at $3.58/hr. The region benefits from massive hyperscaler deployment and an active secondary market that pushes down prices. In major cities like San Francisco or Toronto, you can rent an A100 for under $1.00/hour — often with no contract.
- EuropeEuropean prices for A100s typically range from $1.58 to $3.27/hr, with Germany at $2.28/hr and France at $2.75/hr. High energy costs and less aggressive pricing from cloud providers keep the floor higher than in North America.
- Asia, Middle East, and South AmericaThese regions see significantly higher A100 pricing — in some cases exceeding $4.00/hour. A data scientist in Riyadh or São Paulo might pay 3–4x what a peer in Chicago pays for the same GPU.
Despite its widespread availability, the A100’s price is still strongly shaped by local market forces.
H100 Pricing: Geography Exacerbates Scarcity
The NVIDIA H100, built on the Hopper architecture, remains one of the most powerful GPUs in the market — but its pricing varies dramatically depending on geography. In fact, the hourly cost of accessing an H100 in 2025 can differ by more than 6x depending on the region.
In North America, pricing is comparatively low and stable, averaging around $4.12/hr, with some platforms offering rates as low as $1.99/hour. Early deployment by providers like Lambda Labs, Jarvislabs, and GMI Cloud, along with robust participation in secondary markets, has created a more competitive and transparent pricing environment.
Europe, while relatively well-provisioned, faces higher prices. The average rental cost is approximately $4.12/hour, typically ranging from $2.00–$6.39/hr. Higher energy costs, limited spot market liquidity, and slower procurement cycles contribute to this regional premium. Prices fluctuate between different countries a lot as well: France $3.00/hr vs Germany $6.22/hr and Sweden $6.39/hr.
The Global South — including regions such as Africa, South America, and parts of the Middle East — experiences the steepest prices. H100 rentals in these areas can exceed $9.00/hour, with averages between $5.93–$10.68/hr. Limited hyperscaler footprint, weaker infrastructure, and constrained supply chains force many users into long-term reservations or inflated on-demand rates.
A VFX studio in São Paulo may pay $9.00/hour per H100, while a startup in Texas can access the same GPU for just $2.50/hour — a 260% difference based solely on location.
Ultimately, the question for teams isn’t just whether they can get access to H100s — but where they can get them affordably and reliably. In many emerging markets, geography is still a gating factor for large-scale AI compute access.
What’s Causing the Geographic Price Gaps?
Pricing differences of this magnitude don’t happen by accident. They’re driven by a combination of macro, technical, and policy-level factors, including:
| Factor | Impact |
|---|---|
| Supply Chain & Trade Policy | Export controls, taxes, and shipping delays limit supply in emerging markets |
| Infrastructure Maturity | Regions with limited datacenter infrastructure face higher deployment and cooling costs |
| Power & Energy Economics | GPU farms in areas with cheap electricity offer better rates — high-power H100s accentuate this |
| Market Liquidity | Secondary markets and auction-style pricing in North America create more efficient price discovery |
| Demand vs. Deployment | In high-growth markets, demand is outpacing hyperscaler buildout, leading to bottlenecks |
As with housing or bandwidth, pricing reflects not just the product but the local ability to support and distribute it.
Real-World Examples
These aren’t abstract market dynamics — they’re impacting organizations right now.
- University Research (Germany): A research team pays ~$2/hr per A100. The same workload in the UAE could cost $4.00/hr. On a month-long training run, that’s a 2.2x cost multiplier.
- Visual Effects Studio (Brazil): A post-production studio needs 8x H100s for a rendering job. In Brazil, the bill comes to nearly $15,000/week. Shifting to North America could cut costs by 40–60%, depending on latency tolerance.
- AI Startups (India & MENA): Startups often wait days for GPU access or settle for A100s when they need H100s. Geography creates a performance and opportunity gap — not just a pricing gap.
Why It Matters to Teams, Operators, and Investors
For AI Teams & Enterprises
Location-based compute arbitrage can cut model training and inference costs by 30–60%. This is a tactical lever that few organizations are using — but should.
For GPU Operators
Deploying in the right geography isn’t just about latency — it’s about optimizing revenue per GPU hour. In some cases, listing H100s in demand-constrained regions earns 3x higher margins.
For Investors
As GPUs become assets in compute marketplaces, pricing risk is increasingly location-driven. Valuing GPU infrastructure means understanding both technical specs and regional context.
Final Thought: Compute Is No Longer Location-Agnostic
AI infrastructure may be virtual, but its economics are still very much physical.
While teams obsess over model architecture and performance, they often miss the variable hiding in plain sight: where the compute actually lives. In 2025, that can be the difference between scaling affordably — or not scaling at all.
At Silicon Data, we believe that geographic price transparency and cross-market liquidity are the next frontiers in AI infrastructure strategy.
The question isn’t just: “What GPU should I use?”
It’s: “Where should my GPU live?”