H100 Price Spike: Understanding the 10% Surge in GPU Rental Costs
H100 GPU rental prices jumped 10% in just four weeks. Explore what drove the spike.

Just when we thought the GPU rental market was finally stabilizing, the H100 threw us a curveball. Our GPU Rental Index revealed a startling 10% price jump for H100 rentals between December 9, 2025 and January 6, 2026. Hourly rates climbed from $2.00 to $2.20 in just four weeks. This marks the largest short-term increase since mid-2025, and here's the twist: it happened in isolation. A100 and B200 pricing remained rock-solid during the same period. This wasn't a market-wide trend. It was a targeted spike that tells us something important about the underlying fragility of premium AI infrastructure. Even as the broader GPU market matures and normalizes, we're seeing that localized volatility isn't going away. It's just getting more selective about where it strikes.
The Data: What Our GPU Rental Index Revealed
As we analyze the latest GPU marketplace data, one trend stands out starkly. Our H100 price tracking reveals a sudden, counter-seasonal surge that defied both historical patterns and recent market expectations.
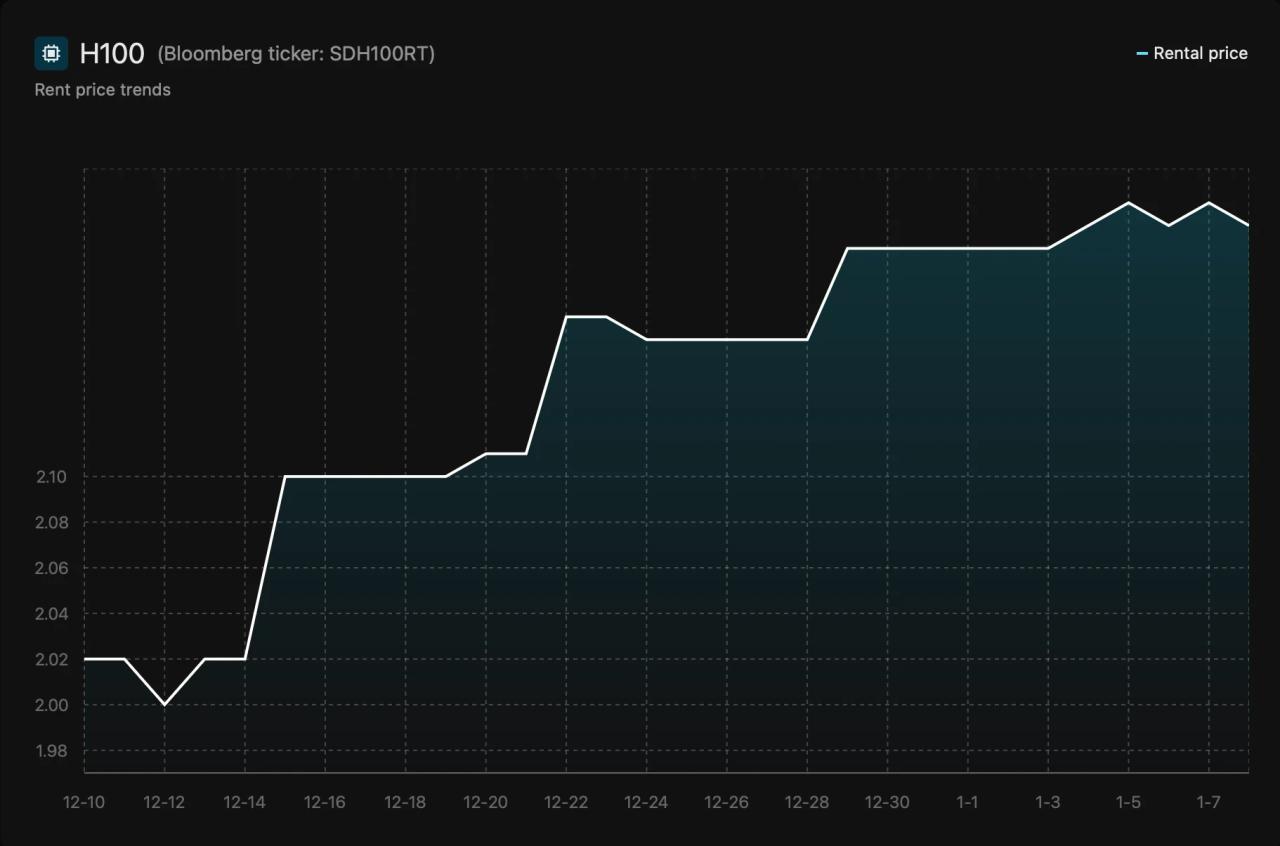
The Timeline:
- December 9, 2025: $2.00/hr baseline
- January 6, 2026: $2.20/hr peak
- Change: +10% in four weeks
- Context: Largest short-term price movement since mid-2025
What makes this particularly noteworthy? Timing. December typically brings a seasonal slowdown in cloud rental rates as enterprises wind down projects and defer workloads over the holidays. Historically, we've observed price softening during this period, not spikes. Yet 2025 flipped the script entirely.
This also represents a significant pricing milestone when viewed against the broader trend. H100 cloud rates plummeted from around $8/hr in early 2024 to the $1.50-$3.00/hr range by late 2025 across specialist providers. Major hyperscalers like AWS slashed prices by 44-45% mid-year. The normalization trend was clear and consistent. Until it wasn't.
GPU Pricing Comparison (Dec 9 - Jan 6, 2026):
- H100: +10% ($2.00 → $2.20/hr)
- A100: Stable (no significant change)
- B200: Stable (no significant change)
This isolation is what caught our attention. When only one SKU moves while its peers sit still, that's a signal worth investigating. The gpu cost dynamics at play here tell a story about supply constraints, demand imbalances, and the unique position H100 occupies in the market hierarchy.
Supply-Side Constraints: The Scarcity Economics at Play
We've observed a fascinating paradox over the past year. While overall H100 lead times improved dramatically through 2025, shrinking from over 50 weeks in 2023 to just 8-12 weeks by late 2024, spot market availability told a different story during this critical December-January window. The rental market remained surprisingly tight.
Here's what happened on the supply side. Hyperscalers and major cloud providers prioritized their allocation policies toward reserved capacity and long-term contracts. That squeezed on-demand inventory in secondary markets. We saw this play out most dramatically in Europe and Asia, where H100 spot capacity was already scarcer than in North America. When those regional supply constraints hit during a demand spike, availability constraints became acute. Buyers willing to pay premiums for immediate access had fewer options, and that scarcity economics drove prices up.
The broader context matters too. Yes, the worst supply chain disruptions have eased. CoWoS packaging bottlenecks at TSMC, HBM3 supply, and substrate availability (those TRX5090 substrates from Ibiden and Unimicron) are all in better shape than 2023-2024. But "better" doesn't mean "elastic." The infrastructure still operates near capacity limits. When a demand shock hits, there's minimal buffer on the supply side to absorb it. The system has very little slack.
We also noticed how vendor discounts and pricing strategies created a two-tier market. Large enterprise buyers with long-term contracts and strong vendor relationships? Largely insulated from the spike. They locked in capacity months ago. Spot market users and smaller buyers without those negotiated deals? They bore the full pricing pressure. This allocation dynamic meant the pain wasn't distributed evenly. It concentrated in the on-demand rental segment where pricing visibility is already poor and supply shortage effects amplify quickly.
Demand-Side Drivers: Year-End Training Cycles and Budget Pressures
From our analysis of late 2025 market dynamics, several powerful demand-side factors converged, creating significant GPU demand and pricing pressure. We saw AI infrastructure demand far outpace available supply, driven by three distinct but overlapping forces.
End-of-Year Training Deadlines
Teams across the industry were racing the clock. Large-scale model training jobs had to finish before the close of 2025, and that created concentrated, time-sensitive demand. H100s became the target of choice for good reason. Their FP8-optimized workloads and superior performance for frontier model training make them irreplaceable for certain tasks. This wasn't organic AI demand growth spread evenly across the year. These were industry demand spikes tied directly to organizational planning cycles and arbitrary calendar deadlines. When everyone's trying to cross the finish line at the same time, you get a demand shock.
Budget Utilization Cycles
Then there's the "use-it-or-lose-it" phenomenon. Organizations with fiscal year-end in December faced a familiar pressure: spend your allocated infrastructure budget or watch it vanish. We believe a significant portion of the price movement came from this dynamic. Teams accelerated H100 usage not because workloads demanded it, but because unspent funds would lapse. This created artificial demand shocks completely disconnected from actual training needs. It's a classic demand imbalances policies issue where procurement timing and budget cycles distort market conditions in predictable but powerful ways.
Enterprise Market Behavior
Zooming out, the sustained pressure from the demand side reflects a broader shift. Both hyperscalers and mid-sized enterprises continue to pour resources into AI infrastructure. Even as Blackwell begins ramping up, H100 demand hasn't slackened. Why? The H100 now occupies what we call the "mainstream high-end" tier. It's no longer the bleeding edge, but it's still premium. That positioning creates sustained GPU demand from diverse buyer segments: research labs fine-tuning domain-specific models, enterprises running RAG pipelines, startups training production-scale systems. This broad base of demand interacts with those supply constraints we discussed earlier. The result? Even short windows of tightened availability create pricing pressure that ripples through rental rates quickly.
Market Forces and Price Discovery in a Constrained Environment
As we navigate the GPU marketplace into 2026, we find that a clear market price for H100 compute remains elusive. The process of price discovery is profoundly challenging. This is not a transparent commodity market. Our research reveals a stark pricing chasm: H100 GPUs rent for as low as ~$1.90 per hour on specialist providers like Hyperstack and Nebius, while hyperscalers like AWS. Azure and GCP can charge over $4 for comparable configurations in the US.
That's not a minor variance. It's a 2× spread on what should theoretically be the same product. The fragmentation explains much of this. Cloud providers, specialized GPU clouds, decentralized marketplaces, and resale platforms all operate with different cost structures, service levels, and target customers. Infrastructure costs vary wildly (power, cooling, data center location). Pricing strategies diverge based on whether a provider is optimizing for enterprise SLAs or raw compute arbitrage. The result? Massive opacity in what constitutes true market price.
This pricing visibility problem amplifies market volatility. When a demand spike hits and buyers need capacity fast, they lack clear reference points. Is $2.20/hr for an H100 expensive right now, or cheap? Depends entirely on where you're looking and what alternatives you have access to. During tight market conditions, these pricing tiers compress in unpredictable ways. Hyperscalers with deep capacity reserves might hold prices steady, betting on long-term customer relationships. Smaller providers with limited inventory might spike rates aggressively to capture short-term premiums from desperate buyers.
Market shifts add another layer of complexity. The introduction of H200 and upcoming Blackwell creates ceiling effects on H100 premiums. Rationally, buyers won't pay cutting-edge prices for last-generation silicon. But during short-term availability constraints, rational pricing breaks down. Buyers willing to pay premium rates for immediateaccess drive temporary price movements that don't reflect long-term value. Those spikes create noise in the price discovery process, making it harder for everyone to gauge what fair market price actually is. And in a fragmented, opaque marketplace, noise is expensive.
Why H100 Alone? Understanding the Isolated Spike
We've closely monitored the GPU market, and a fascinating trend emerged between December 9th and January 6th. An isolated 10% price spike hit the H100, while other key GPUs remained stable. This divergence is not an anomaly; it reflects sophisticated market segmentation and specific supply-demand dynamics.
The H100 occupies a completely different position. It sits in a unique sweet spot: constrained enough to be highly sensitive to demand fluctuations, yet essential enough for high-end training workloads that buyers have limited substitution options. The performance gap matters. The H100's FP8 capabilities and training throughput are non-negotiable for certain tasks.
This creates what we call low elasticity of supply in the hourly rental market. When demand spikes, there's no quick way to flood the market with more H100 capacity. Long-term contracts have already soaked up much of the allocation. What's left in the spot market is a relatively thin layer of availability. A modest uptick in demand creates disproportionate pricing pressure.
The scarcity economics here are specific and structural. Even as the broader GPU market matures, the H100 remains vulnerable to these isolated pockets of volatility. It's a reminder that cost analysis needs to happen at the SKU level. Treating "GPUs" as a single category misses these crucial dynamics. The gpu market dynamics for H100 are fundamentally different from those governing A100, and wildly different from inference-focused chips. One-size-fits-all assumptions about pricing trends will lead you astray.
Future Outlook: What This Means for GPU Market Dynamics
Let us be clear on what this recent activity does not signal. We do not view it as the precursor to renewed, widespread GPU price hikes or a reversal of the broader H100 pricing normalization trend. Research and forward indicators confirm that supply chain dynamics continue to improve. CoWoS capacity is expanding. HBM availability is better. General price expectations for 2026 point toward stabilization and modest further declines as Blackwell takes over the premium tier and H100 transitions to mainstream workhorse status.
What this spike does reveal is the persistence of structural vulnerabilities in premium GPU markets. Even as overall capacity expands and manufacturing bottlenecks ease, the combination of concentrated demand (everyone training models on the same planning cycles), tight allocation policies (hyperscalers prioritizing long-term contracts), and limited spot market elasticity creates perfect conditions for localized price movements. These aren't smooth, predictable market shifts. They're sharp, isolated spikes driven by temporary imbalances between supply and demand.
For organizations dependent on AI infrastructure, this means adaptive procurement isn't optional. Static strategies assuming stable pricing will get caught flat-footed when the next spike hits. Market monitoring, diversified sourcing across provider tiers, workload flexibility, and proactive capacity planning are now core competencies, not IT housekeeping. The gpu market dynamics we're seeing aren't a bug in the system. They're a feature of how premium compute markets work when demand consistently pushes against constrained supply.
Get Real-Time GPU Market Intelligence
The recent 10% H100 price spike underscores a critical truth: navigating this market without real-time intelligence is a high-stakes gamble. We see how a fragmented landscape with prices ranging from $1.90 to $7 per hour for the same GPU creates massive exposure. When pricing can jump 10% in four weeks while you're locked into quarterly budget forecasts, you need tools that provide actual pricing visibility, not guesswork. GPU market intelligence, predictive GPU pricing models, and comprehensive historical data analysis aren't luxuries anymore. They're essential infrastructure for anyone making serious compute procurement decisions. Performance benchmarking across providers and real-time price indexing prevent costly mistakes and missed opportunities.
Ready to make smarter GPU procurement decisions? Silicon Data serves traders, financial institutions, compute buyers, data centers, and AI leaders with the market intelligence they need to stay ahead. Our platform delivers real-time GPUprice indexing, performance benchmarking, predictive pricing analytics, carbon insights for compute, and seamless API integration for your existing workflows. Whether you're optimizing a trading strategy around compute arbitrage or planning enterprise AI infrastructure budgets, we provide the data and analysis that turn market volatility into competitive advantage. Talk to our sales team to learn how Silicon Data can transform your approach to GPU procurement and market positioning.