OpenAI API Pricing Per 1M Tokens
A comprehensive March 2026 guide to OpenAI API pricing per 1M tokens. Compare GPT-5.4, GPT-5.4 Pro, o3-pro, and mini model rates across all service tiers.

A practical March 2026 guide to token economics, model rates, and cost control
The unpleasant surprise in AI budgets rarely comes from a single number on the pricing page. It comes from the interaction of model choice, context length, output verbosity, tool calls, and routing decisions. OpenAI’s price sheet in 2026 is still readable, but it is no longer simple.
GPT-5.4 now anchors the general-purpose lineup, GPT-5.4 Pro sits at the premium end, and long-context requests above 272K input tokens move onto a more expensive schedule. At the same time, batch, flex, priority, embeddings, file search, web search, and prompt caching all change the real bill. This guide breaks the structure down into plain operating terms: what the current price ladder looks like, where teams overspend, and which levers actually reduce cost.
| Three budget rules that matter most in 2026• Output tokens still dominate many production bills. • Crossing 272K input tokens on GPT-5.4 is a pricing event, not just a longer prompt. • The recent story is catalog expansion more than constant repricing. |
|---|
Understanding OpenAI's Token-Based Pricing Structure
What Are Tokens?
Tokens are the units OpenAI models process internally. A token can be as short as a single character or as long as a full word, depending on language and context. OpenAI’s own rules of thumb remain useful: one token is roughly four characters, roughly three-quarters of a word, and 100 tokens is about 75 words in English.
That estimate matters because tokenization is not linguistically fair. Non-English text often produces a higher token-to-character ratio, which means two prompts of similar length can generate different bills. In multilingual products, that is not a rounding error; it can become a planning assumption.
For budgeting purposes, think in four buckets: input tokens, output tokens, cached tokens, and model-internal reasoning activity that affects the output side of the bill. Costs therefore behave more like metered compute than like a simple per-request API charge.
The Million-Token Standard
The per-million-token unit is now the common language across major model providers. That standard makes comparison easier because teams can evaluate OpenAI, Anthropic, and DeepSeek on the same basic meter before they layer in latency, quality, or tooling.
The key phrase is like-for-like. Standard inference should be compared with standard inference. Fine-tuning, embeddings, web search, and file-search charges belong on separate lines. Once those categories get mixed into a single table, otherwise good comparisons become noisy.
A clean forecasting model therefore works at three levels: cost per request, cost per feature, and cost per month. The math is simple; the discipline is in keeping the categories separate.
Pricing Tiers Overview
OpenAI’s pricing model now varies not only by model but also by service tier. Standard is the default synchronous option. Batch is the low-cost asynchronous path for jobs that can finish within 24 hours. Flex sits in between for lower-priority work, and Priority is the premium tier for lower and more consistent latency.
Batch is the cleanest savings lever because supported models are priced at 50% of standard rates. Flex follows the same cost logic for tokens, but it trades that discount for slower response times and occasional resource unavailability. Priority does the opposite: it protects latency, but at a materially higher price.
GPT-5.4 adds one more crucial wrinkle. The published short-context rate applies only below 272K input tokens. Above that threshold, OpenAI charges 2x input and 1.5x output for the full session under standard, batch, and flex. For long-document or agentic workloads, that threshold matters as much as the model name.
| Tier | How it works | Input* | Cached* | Output* | Best fit |
|---|---|---|---|---|---|
| Standard | Default synchronous tier | $2.50 | $0.25 | $15.00 | Balanced production traffic |
| Batch | Up to 24h turnaround; 50% discount | $1.25 | $0.13 | $7.50 | Offline jobs, backfills, evals |
| Flex | Lower-priority beta tier | Batch-rate | Extra cache savings | Batch-rate | Non-production or tolerant async work |
| Priority | Lower and more consistent latency | $5.00 | $0.50 | $30.00 | High-value user-facing requests |
Table 1. GPT-5.4 short-context rates as a reference point across OpenAI service tiers. *Per 1M tokens.
The dangerous budgeting mistake is to memorize one GPT-5.4 number and use it everywhere. In practice, the same model can land on four different cost curves depending on service tier, context size, and tool usage.
Token Usage Breakdown: Input vs. Output Costs
Understanding Input Tokens
Input tokens include more than the user’s visible prompt. They also include the system message, any retrieved context, tool outputs reinserted into the prompt, and whatever conversation history the application keeps alive.
That is why retrieval-heavy assistants, coding agents, and long-document analyzers often cost more than a simple chatbot benchmark suggests. The model may be answering one question, but it is often reading pages of hidden context first.
Tool-assisted flows add another layer. OpenAI’s web search, for example, has both tool-call fees and search-content tokens billed at model rates. If finance teams group those charges under a single “LLM spend” bucket, they lose visibility into the real driver.
Output Tokens and Cost Ratios
Output pricing is where the rate-card spread becomes unforgiving. Across the current OpenAI lineup, output commonly costs four to eight times as much as input. GPT-5.4 short-context pricing sits at a 6× output premium, while Nano, Mini, GPT-5, and GPT-5.2 all keep an 8× ratio.
That changes what “optimization” really means. Trimming a prompt helps, but capping answer length, enforcing structured output, or tightening a JSON schema often saves more money than shaving a few words from the input side.
The selected price ladder below makes the spread obvious. The inexpensive base models remain genuinely cheap, but the premium end rises steeply once Pro-class reasoning enters the picture.
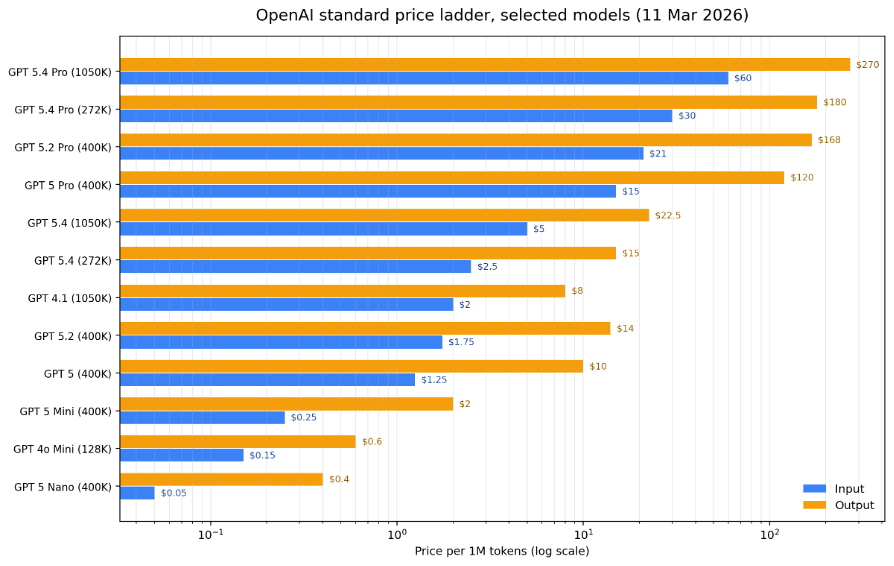
Figure 1. Selected OpenAI standard prices on 11 March 2026. Output premiums widen sharply toward the Pro end of the lineup.
Context size and list price also do not move in a perfectly linear way. GPT-4.1 still offers a 1.05M context window at a lower entry price than GPT-5.4 Pro, while GPT-5.4’s long-context schedule deliberately charges a premium for million-token workloads.
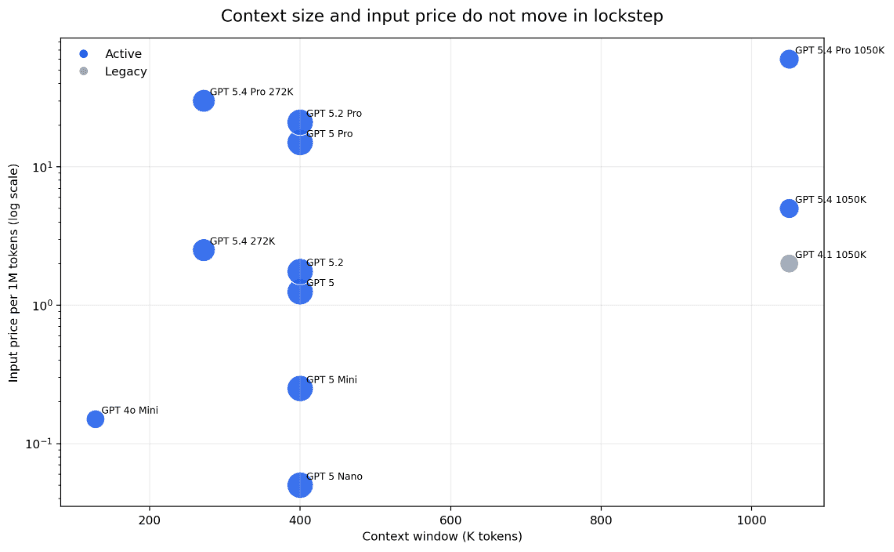
Figure 2. Larger context windows matter, but they do not map cleanly to input price on their own.
Calculating Total Token Usage
The base formula is still straightforward: total cost equals input tokens multiplied by the input rate, plus output tokens multiplied by the output rate, plus any tool fees or service-tier premiums. The trick is to avoid hiding those extras inside a blended average.
For example, a request with 4,000 input tokens and 1,500 output tokens on GPT-5.4 short-context pricing costs 4,000/1,000,000 × $2.50 + 1,500/1,000,000 × $15.00 = $0.0325. That looks tiny until it becomes 100,000 calls.
OpenAI’s Tokenizer and the `tiktoken` library remain the safest tools for pre-flight estimates, while live API usage metadata tells you what actually happened in production. The most reliable internal dashboard logs average input, output, and cache reuse by feature—not just by model.
| The formula that still does most of the workTotal cost = (input tokens ÷ 1,000,000 × input rate) + (output tokens ÷ 1,000,000 × output rate) + tool fees If a long-context threshold, file-search charge, web-search call, or priority tier applies, add it explicitly instead of burying it in an average. |
|---|
Model Pricing Comparison and Rates
GPT-5 Series Pricing Overview
OpenAI now positions GPT-5.4 as the flagship general-purpose API model and recommends it as the default place to start when quality matters. GPT-5.4 Pro is the premium option for harder problems where latency is secondary to depth and accuracy.
A March 11, 2026 snapshot of current model pricing shows a clear ladder from GPT-5 Nano and GPT-5 Mini up through GPT-5, GPT-5.2, GPT-5.4, and finally the Pro variants. That is the real near-term story: the catalog is broadening faster than the core standard rates are moving.
The biggest operational change is the split between short and long context on GPT-5.4 and GPT-5.4 Pro. Short-context GPT-5.4 starts at $2.50 input and $15 output per million tokens; the long-context schedule moves to $5.00 and $22.50. GPT-5.4 Pro moves from $30/$180 to $60/$270.
| Model | Status | Context | Input | Output | Ratio |
|---|---|---|---|---|---|
| GPT-4o Mini | Active | 128K | $0.15 | $0.60 | 4.0× |
| GPT-5 Nano | Active | 400K | $0.05 | $0.40 | 8.0× |
| GPT-5 Mini | Active | 400K | $0.25 | $2.00 | 8.0× |
| GPT-5 | Active | 400K | $1.25 | $10.00 | 8.0× |
| GPT-5.2 | Active | 400K | $1.75 | $14.00 | 8.0× |
| GPT-5.4 | Active | 272K | $2.50 | $15.00 | 6.0× |
| GPT-5.4 | Active | 1.05M | $5.00 | $22.50 | 4.5× |
| GPT-5 Pro | Active | 400K | $15.00 | $120.00 | 8.0× |
| GPT-5.2 Pro | Active | 400K | $21.00 | $168.00 | 8.0× |
| GPT-5.4 Pro | Active | 272K | $30.00 | $180.00 | 6.0× |
| GPT-5.4 Pro | Active | 1.05M | $60.00 | $270.00 | 4.5× |
| GPT-4.1 | Legacy | 1.05M | $2.00 | $8.00 | 4.0× |
Table 2. Corrected selected lineup of OpenAI text-token prices, 11 March 2026.
Pricing Breakdown Across the GPT-4 Family
GPT-4.1 remains an important reference model because it pairs a very large 1.05M context window with a relatively modest $2 input / $8 output rate. It is no longer the headline product, but it still shows how aggressive OpenAI’s price/performance history has become.
GPT-4o Mini also continues to matter. At $0.15 input and $0.60 output, it changes the economics of experimentation, regression testing, multimodal utilities, and low-margin automation in a way premium reasoning models simply cannot.
One caveat is especially important for pricing tables that circulate online: versioned rows such as `gpt-4o-2024-08-06` and `gpt-4o-mini-2024-07-18` appear in OpenAI’s fine-tuning tables. If those rows show unusually high “input” prices in a comparison, you may actually be looking at training prices mixed into an inference chart.
Competitive Landscape
OpenAI does not compete in a vacuum. Anthropic’s Sonnet 4.6 and Opus 4.6 use the same per-million-token convention, while DeepSeek V3.2 remains unusually cheap on raw token prices.
That does not make the decision trivial. OpenAI’s GPT-5.4 emphasizes frontier general-purpose performance with a large tool ecosystem. Anthropic advertises 1M-context beta access for Sonnet 4.6 and Opus 4.6. DeepSeek V3.2 is cost-aggressive, but its API context limit is 128K and its product profile is different.
The comparison below uses DeepSeek’s cache-miss input price for the closest apples-to-apples view, with the cache-hit rate called out separately in the notes.
| Provider | Model | Input | Output | Ratio | Context / note |
|---|---|---|---|---|---|
| OpenAI | GPT-5.4 | $2.50 | $15.00 | 6.0× | 1.05M (higher rate above 272K) |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | 5.0× | 1M beta on API |
| Anthropic | Claude Opus 4.6 | $5.00 | $25.00 | 5.0× | 1M beta on Claude Platform |
| DeepSeek | V3.2 | $0.28 | $0.42 | 1.5× | 128K (cache miss rate shown) |
Table 3. Current first-party list prices from OpenAI, Anthropic, and DeepSeek pages.
Batch API Discounts
OpenAI’s Batch API is one of the cleanest cost levers in production. If a job can complete within 24 hours, supported models are priced at half the synchronous token rate. That is often the difference between a viable backfill and a deferred one.
Anthropic also advertises 50% savings with batch processing. In both ecosystems, the best use cases are evaluations, offline summarization, nightly enrichment, ETL-style extraction, and other workloads that do not sit on the critical user path.
Embeddings and Specialized Models
The cheapest OpenAI workloads are not always chat completions. Embeddings are priced far below general-purpose generation: `text-embedding-3-small` at $0.02 per million tokens, `text-embedding-3-large` at $0.13, and `text-embedding-ada-002` at $0.10. Moderation remains free.
Tooling creates a different layer of spend. File search storage is billed by stored data, file-search calls are billed separately, and web search combines per-call charges with search-content tokens billed at model input rates.
From a finance perspective, that means embedding, search, and container costs deserve their own dashboard lines. Otherwise teams over-attribute spend to the model itself when the orchestration layer is doing much of the billing.
| Category | Item | Cost | Note |
|---|---|---|---|
| Embedding | text-embedding-3-small | $0.02 / 1M tokens | Batch: $0.01 / 1M |
| Embedding | text-embedding-3-large | $0.13 / 1M tokens | Batch: $0.065 / 1M |
| Embedding | text-embedding-ada-002 | $0.10 / 1M tokens | Batch: $0.05 / 1M |
| Safety | omni-moderation | Free | OpenAI moderation models |
| Tooling | File search storage | $0.10 / GB-day | First 1GB free |
| Tooling | File search tool call | $2.50 / 1K calls | Responses API |
| Tooling | Web search | $10 / 1K calls | Search content tokens billed at model rates |
| Tooling | Web search preview (non-reasoning) | $25 / 1K calls | Search content tokens are free |
| Tooling | Containers (1GB default) | $0.03 / container | Moves to $0.03 / 20 min starting Mar 31, 2026 |
Table 4. OpenAI embeddings, moderation, and selected built-in tool charges.
Cost Calculation Methods and Budgeting Strategies
Manual Cost Calculation Formula
Every budgeting system should preserve the raw cost equation before it adds forecasting layers. Once you know the average input and output shape of a task, the base price is just arithmetic.
Where teams go wrong is by hiding thresholds or extras in a blended average. Long-context pricing, priority processing, file-search storage, web-search calls, and container usage should be added as separate terms. A clean formula makes pricing changes visible.
Pricing Calculators and Tools
The official pricing page and the model-specific docs are still the source of truth. For GPT-5.4, the model guide and pricing page together explain the 1M context window, the 272K threshold, and the separate long-context schedule.
Before shipping a feature, estimate token counts with OpenAI’s Tokenizer or `tiktoken`; after shipping, validate assumptions with live response metadata and usage dashboards. Billing tools tell you what happened. Token estimation prevents it.
The most useful internal calculator is usually small: request volume, average input, average output, cache reuse, tool-call frequency, and routing mix. That is enough to produce reliable monthly forecasts without pretending the future is more certain than it is.
Token Budgeting Framework
Start with a per-feature budget rather than a single blended monthly cap. Search, drafting, extraction, summarization, and code generation have different token shapes and should rarely share one assumption.
Then convert that monthly budget into practical operating ceilings such as cost per 1,000 requests or cost per completed task. Those are the levers product and engineering teams can actually optimize against.
In Scenario A below, 1,000 requests with 2,000 input tokens and 500 output tokens range from $0.30 on GPT-5 Nano to $255 on GPT-5.4 Pro long-context. Scenario B uses a much smaller prompt and answer pair, compressing the spread without changing the ranking.
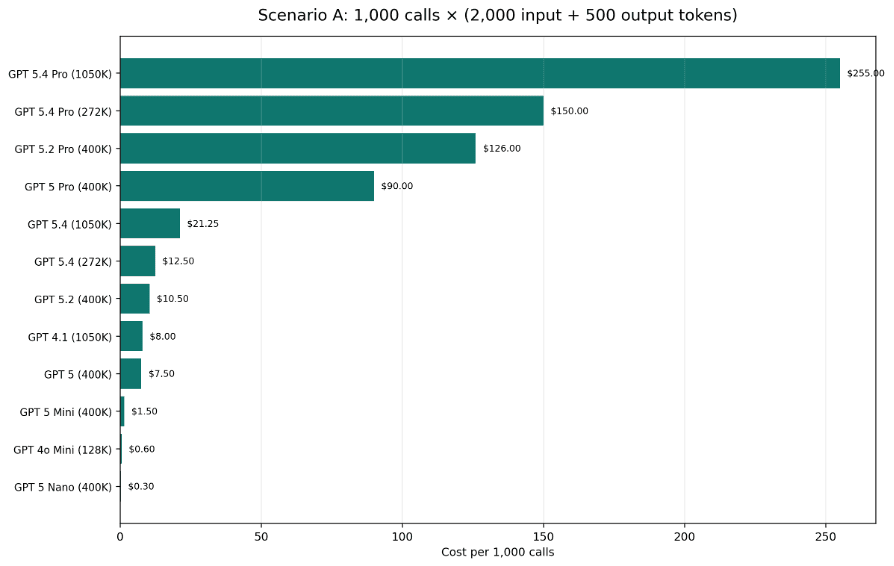
Figure 3. Scenario A: 1,000 requests with 2,000 input and 500 output tokens.
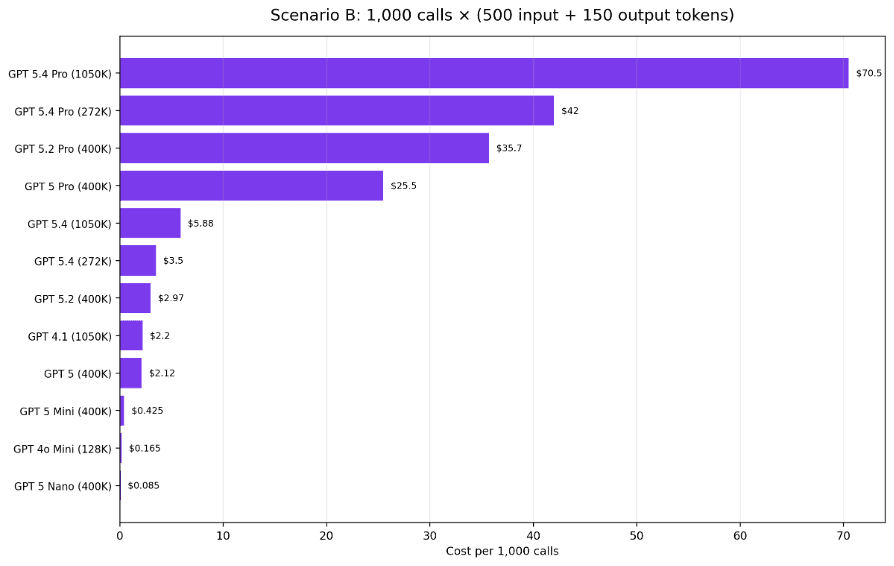
Figure 4. Scenario B: 1,000 requests with 500 input and 150 output tokens.
The short-term history also suggests an important management point: the catalog grows from 36 to 42 named models across the recent 70-day window, while most core standard-inference rates remain flat. Budgeting complexity is rising more because the menu is wider, not because every row changes every week.
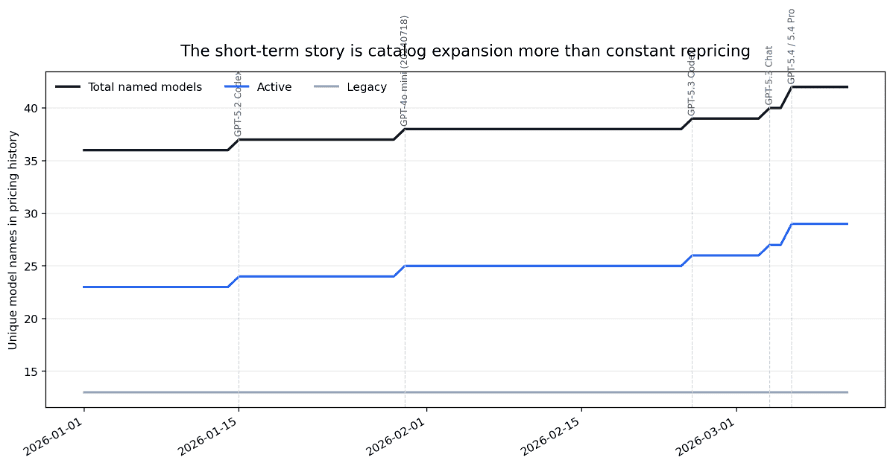
Figure 5. Recent pricing history suggests lineup expansion is a larger management problem than constant repricing.
Optimization Strategies for Cost Efficiency
Prompt Engineering for Token Reduction
Cost optimization usually starts with boring edits: remove boilerplate, collapse duplicated instructions, and define the target output length. Every repeated paragraph in a system prompt becomes a recurring tax.
Ask for exactly what the application needs. A concise JSON object, bullet summary, or fixed template often saves more than an open-ended prompt that invites a long essay back.
Retrieval flows benefit from the same discipline. Summarize or rank long source material before handing it to the most expensive model, and keep only the passages that matter to the decision at hand.
Context Management and Caching
Prompt caching deserves more attention because it attacks both cost and latency. OpenAI says caching can reduce input costs by up to 90% and latency by up to 80%, and it is available automatically on API requests.
That benefit only materializes when the reusable prefix is stable. Keep instructions, policies, schemas, and persistent context in a consistent order so the cache has something meaningful to match.
The same principle applies to chat history. Instead of replaying an entire transcript forever, periodically collapse prior turns into a compact state summary and carry that forward.
Batch Processing and Model Selection
The best routing stack rarely uses one model for everything. Low-stakes classification, triage, enrichment, and testing often belong on GPT-4o Mini or GPT-5 Mini, while harder synthesis or coding tasks can escalate to GPT-5 or GPT-5.4.
Offline workloads should default to batch or flex unless there is a real business reason to pay synchronous or priority rates. The savings compound quickly once request counts are large.
Reserve Pro-class models for cases where quality or reasoning depth clearly changes revenue, compliance, or failure cost. Otherwise the price delta can overwhelm modest quality gains.
Monitoring and Anomaly Detection
Separate dashboards by cost driver: input tokens, output tokens, cached reuse, tool calls, and fallback traffic. One blended ‘AI spend’ line hides the source of anomalies.
Create alerts for three patterns in particular: output-length spikes, long-context threshold crossings, and sudden changes in model-routing mix. Those are common precursors to budget surprises.
Also watch the legacy surface area. When a legacy model still supports a critical workflow, its eventual replacement becomes both a migration task and a pricing event.
Staying Updated on Pricing Changes
Accessing the Official Pricing Page
Treat screenshots and third-party tables as temporary hints, not authoritative references. OpenAI’s pricing docs and model pages are the best place to verify live rates, context tiers, and add-on tool costs.
The deprecations page matters just as much as the pricing page. A model can become a legacy dependency long before its cost line disappears from internal spreadsheets.
Price Updates and Communication
In practice, pricing changes surface through a mix of model pages, launch posts, release notes, and deprecation notices. Teams that buy once and archive a screenshot almost always miss the nuance.
The common failure mode is semantic drift: a row name still looks familiar, but its purpose has changed. Versioned models can shift from active inference relevance to fine-tuning reference status, or tool billing can change without the base model rate moving at all.
Impact of Pricing Updates
The largest pricing impact is often structural rather than nominal. Crossing a context threshold, enabling a tool, or rerouting traffic to a Pro model can overwhelm small list-price differences.
GPT-5.4’s 272K boundary is the clearest example. A request with 250K input tokens and 20K output tokens costs about $0.925 at the short-context rate; a request with 300K input and the same output can jump to about $1.95.
That is why finance teams should track prompt-size distributions, not just averages. Averages hide tail events, and tail events are where many budget overruns begin.
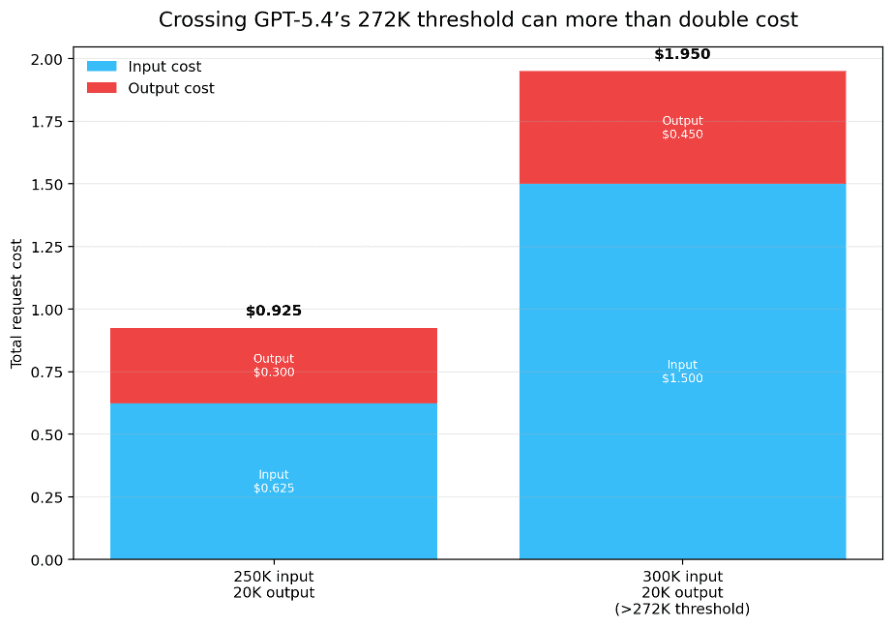
Figure 6. On GPT-5.4, a modest increase in input tokens can push the whole request onto a much more expensive schedule.
Real-World Cost Management Examples
Enterprise Application Case Study
Consider an illustrative enterprise support workflow handling 50,000 interactions per day. At 3,000 input tokens and 800 output tokens per interaction on GPT-5, the monthly run rate is about $17,625.
Now apply three disciplined changes. First, cut prompt bloat and stale history to reduce input tokens by 30%. Second, use caching or reuse to eliminate 25% of calls. Third, route 40% of the remaining traffic to GPT-5 Mini while keeping 60% on GPT-5.
The result is a monthly cost of about $8,128, a 53.9% reduction without changing the product category or abandoning higher-quality models entirely.
The lesson is that savings compound. Token reduction, call reduction, and routing each look incremental on their own; together they reshape the unit economics.
Startup Token Budgeting
A startup with a $5,000 monthly AI budget needs a routing plan before it needs a fancy calculator. One practical split is 15% for development and testing, 60% for production, 20% as growth buffer, and 5% for experiments.
On GPT-5.2, a generation with 4,000 input tokens and 1,500 output tokens costs about $0.028. A $3,000 production allocation therefore buys roughly 107,000 such generations per month. The same task costs about $0.020 on GPT-5 and about $0.004 on GPT-5 Mini.
That spread is why startups should bind models to margin tiers. Use the premium model only where answer quality directly changes revenue, retention, or compliance outcomes.
Good budgeting is not about always picking the cheapest row. It is about paying the premium only when the premium has a measurable business return.
Final Takeaway
OpenAI pricing in 2026 becomes much easier to manage once you separate four layers: the base token rate, the service tier, the context threshold, and the tool stack. Most billing surprises come from mixing those layers together.
The durable playbook is straightforward: measure real token shapes, route work by value, exploit caching and batch, and watch context thresholds closely. Do that, and per-million-token pricing becomes a workable operating metric instead of a source of surprise.
Method Note
Comparisons in this article focus on standard text-token pricing for current or clearly identified models. Fine-tuning, tool fees, embeddings, and scheduled billing changes are called out separately rather than mixed into one apples-to-apples table. When versioned rows map to fine-tuning tables, they are treated as such instead of being used in the live inference ladder.
Reference Links
OpenAI pricing docs: https://developers.openai.com/api/docs/pricing/
OpenAI latest-model guide: https://developers.openai.com/api/docs/guides/latest-model/
OpenAI priority processing: https://developers.openai.com/api/docs/guides/priority-processing/
OpenAI flex processing: https://developers.openai.com/api/docs/guides/flex-processing/
OpenAI deprecations: https://developers.openai.com/api/docs/deprecations/
OpenAI token guide: https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
Anthropic pricing: https://claude.com/pricing
Anthropic Claude Sonnet 4.6: https://www.anthropic.com/claude/sonnet
Anthropic Claude Opus 4.6: https://www.anthropic.com/claude/opus
DeepSeek pricing: https://api-docs.deepseek.com/quick_start/pricing