Anthropic Claude API Pricing 2026
A comprehensive breakdown of Anthropic Claude API pricing for 2026, covering per-token rates for Haiku, Sonnet, and Opus models, batch processing discounts, prompt caching savings, long-context premiums, and cross-provider comparisons.

Early-2026 pricing history plus current public pricing terms checked on March 11, 2026
Key takeaways
- No observed model-context pair changed its base price once listed in the Jan. 1–Mar. 10, 2026 history; the story is portfolio refresh, not constant repricing.
- The premium-tier reset is large: Opus 4.5 and Opus 4.6 at $5 / $25 are 66.7% cheaper than Opus 4 and Opus 4.1 at $15 / $75 for the same token volumes.
- 1M context expands capability, but it is not free in all cases. Anthropic’s public long-context schedule applies premium rates when a request exceeds 200K input tokens.
- Anthropic now publicly posts the commercial levers that materially change effective cost: 50% Batch pricing, prompt caching, tool charges, code execution fees, and seat-plan pricing.
- On raw official list price, Anthropic is not the lowest-cost text API in the market; its strongest 2026 pricing improvement is a cheaper current premium tier than its own legacy Opus baseline.
Method note. This article combines a 69-snapshot Anthropic pricing history from Jan. 1 to Mar. 10, 2026 with official public pricing pages from Anthropic, OpenAI, and Google accessed on Mar. 11, 2026. Historical observations support timing and model-portfolio claims; official web pricing supports current commercial terms and cross-provider comparisons. Cross-provider tables are list-price comparisons, not benchmark-normalized quality rankings.
Anthropic’s Claude API pricing in 2026 is best understood as a three-layer system: base model rates, request-level modifiers, and feature-level charges. The early-2026 history shows stable base rates within each listed model-context pair. What changed was the model mix: 4.6 variants appeared, legacy 3.x lines retired or disappeared, and the active price floor moved from Claude 3 Haiku to Haiku 4.5. Public Anthropic documentation adds the commercial mechanics that matter in production: Batch discounts, prompt caching, long-context premiums, tool pricing, code execution fees, and seat-plan structure.
Introduction to Anthropic Claude API Pricing
Anthropic’s pricing story is much clearer in 2026 because the company now publishes more of the commercial detail directly. That makes it possible to separate base model economics from operational modifiers and from product-plan pricing.
Key Pricing Components
- Base model rate: published input and output token prices for each Claude model family.
- Request modifier: Batch processing, prompt caching, long context, data residency, and fast mode can materially change effective per-token cost.
- Feature charge: server-side tools such as web search and stand-alone code execution can create non-token fees on top of model usage.
Strategic Importance for Cost Management
The first cost decision is model family, not micro-optimization. On the latest observed date, a 10M-input / 2M-output workload costs $20 on Haiku 4.5, $60 on Sonnet 4.5 or 4.6, $100 on Opus 4.5 or 4.6, and $300 on Opus 4 or Opus 4.1. Production teams should therefore choose the cheapest model family that clears the quality bar, then use batching, caching, and context controls to reduce the remainder.
| Metric | Value |
|---|---|
| Historical observation window | 2026-01-01 to 2026-03-10 |
| Daily snapshots | 69 |
| Rows | 825 |
| Unique model names | 12 |
| Unique model-context-price variants | 15 |
| Latest-date active model names | 8 |
| Latest-date active variants | 10 |
| Contexts observed | 195K, 200K, 1M |
| Base input price range in observations | $0.25 to $16.50 |
| Current public pricing cross-check | Public Anthropic pricing checked on 2026-03-11 |
Source note: Historical metrics in Table 1 come from 69 daily Anthropic pricing observations between 2026-01-01 and 2026-03-10. Public pricing cross-check is based on Anthropic pricing pages checked on 2026-03-11.
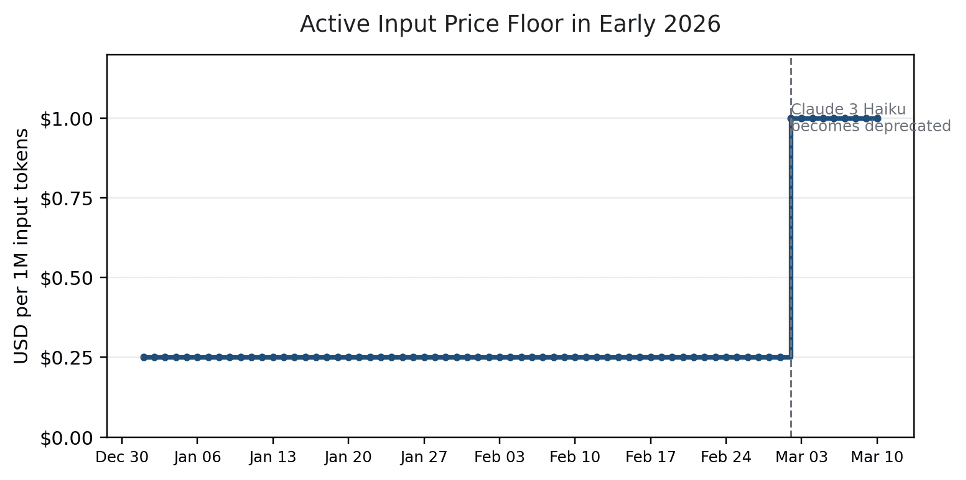
Figure 1. The active input-price floor stayed at $0.25 until Claude 3 Haiku became deprecated on 2026-03-02.
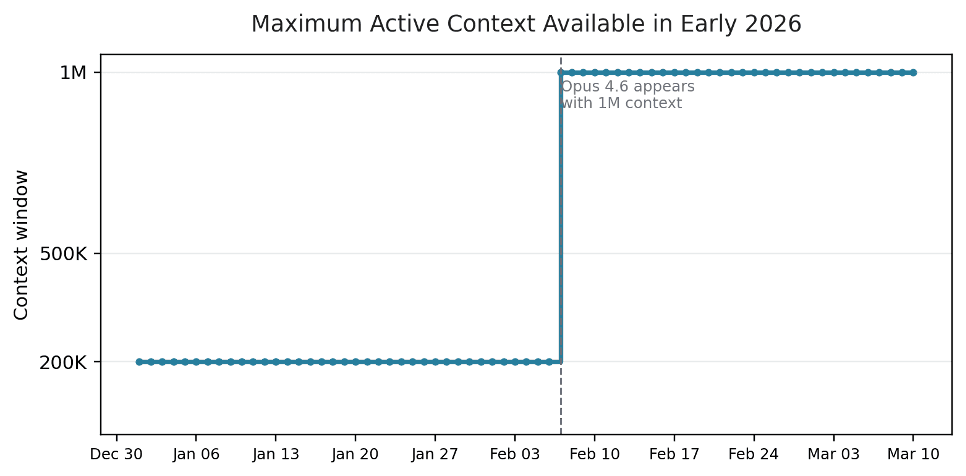
Figure 2. The maximum active context jumped from 200K to 1M on 2026-02-07 and stayed there through the latest observed date.
Pricing Structure and Models for 2026
Token Pricing Breakdown
In the historical catalog, every base model line prices output at exactly 5x input. That keeps budgeting simple at the base-rate layer: output-heavy agents, assistants, and document-generation workflows will dominate spend faster than input-heavy extraction or classification pipelines. The same historical record also shows two legacy 195K variants—Sonnet 4 195K and Opus 4 195K—each carrying a 10% premium versus the corresponding 200K variant.
Claude API Pricing Structure
Table 2 shows the latest observed Anthropic rate card. It combines current active models with the last still-visible deprecated baseline so the current price ladder and the legacy floor can be seen together.
| Model | Status | Context | Use case | Input ($/1M) | Output ($/1M) | 10M in + 2M out |
|---|---|---|---|---|---|---|
| 3 Haiku | Deprecated | 200K | Chatbot | $0.25 | $1.25 | $5.00 |
| Haiku 4.5 | Active | 200K | Chatbot | $1.00 | $5.00 | $20.00 |
| Sonnet 4 | Active | 200K | Coding | $3.00 | $15.00 | $60.00 |
| Sonnet 4.5 | Active | 200K | Coding | $3.00 | $15.00 | $60.00 |
| Sonnet 4.6 | Active | 1M | Coding | $3.00 | $15.00 | $60.00 |
| Sonnet 4 | Active | 195K | Coding | $3.30 | $16.50 | $66.00 |
| Opus 4.5 | Active | 200K | Coding | $5.00 | $25.00 | $100.00 |
| Opus 4.6 | Active | 1M | Coding | $5.00 | $25.00 | $100.00 |
| Opus 4 | Active | 200K | Coding | $15.00 | $75.00 | $300.00 |
| Opus 4.1 | Active | 200K | Coding | $15.00 | $75.00 | $300.00 |
| Opus 4 | Active | 195K | Coding | $16.50 | $82.50 | $330.00 |
Source note: Table 2 reflects the latest observed date in the 2026 historical pricing series: 2026-03-10.
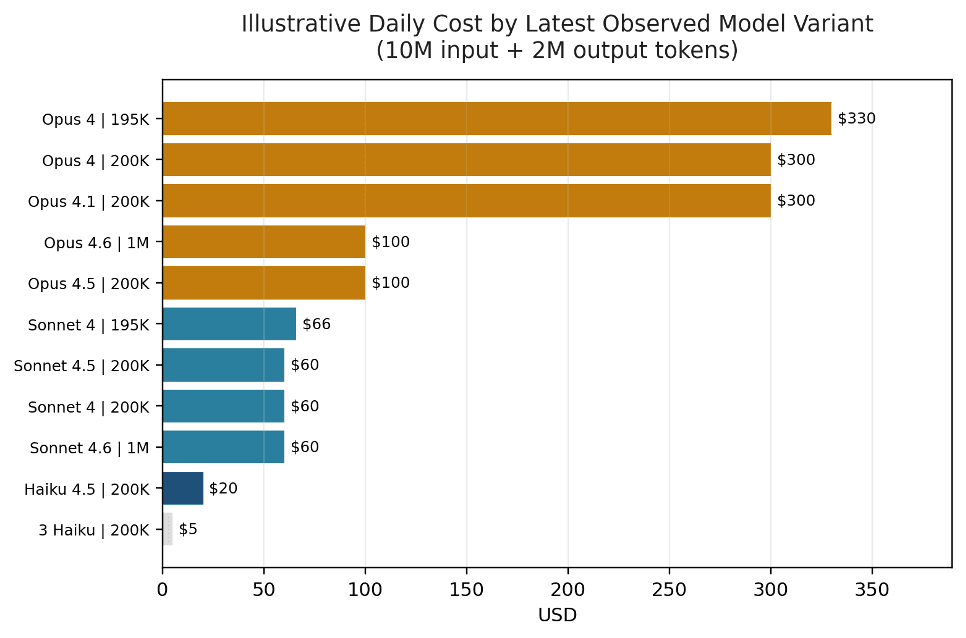
Figure 3. On a 10M-input / 2M-output workload, current Opus 4.5 and Opus 4.6 cost one-third of the legacy Opus 4 / 4.1 baseline.
Cost Implications and Context Windows
Context growth is meaningful, but the pricing story has nuance. The historical record shows Opus 4.6 arriving with 1M context on Feb. 7 and Sonnet 4.6 joining on Feb. 18 at the same base family rates as 4.5. Anthropic’s public pricing docs, however, make clear that requests exceeding 200K input tokens on supported 1M-context models switch to long-context pricing. In practice, 1M capability expands routing flexibility but should still be governed with explicit token thresholds.
| Model(s) | ≤200K input/request | >200K input/request | Change vs base | Key note |
|---|---|---|---|---|
| Sonnet 4 / 4.5 / 4.6 | $3.00 / $15.00 | $6.00 / $22.50 | +100% input, +50% output | Requests are charged at long-context rates when input exceeds 200K. |
| Opus 4.6 | $5.00 / $25.00 | $10.00 / $37.50 | +100% input, +50% output | Fast mode is priced separately and does not use the Batch API. |
Source note: Official Anthropic long-context pricing for supported 1M-context models, checked on 2026-03-11.
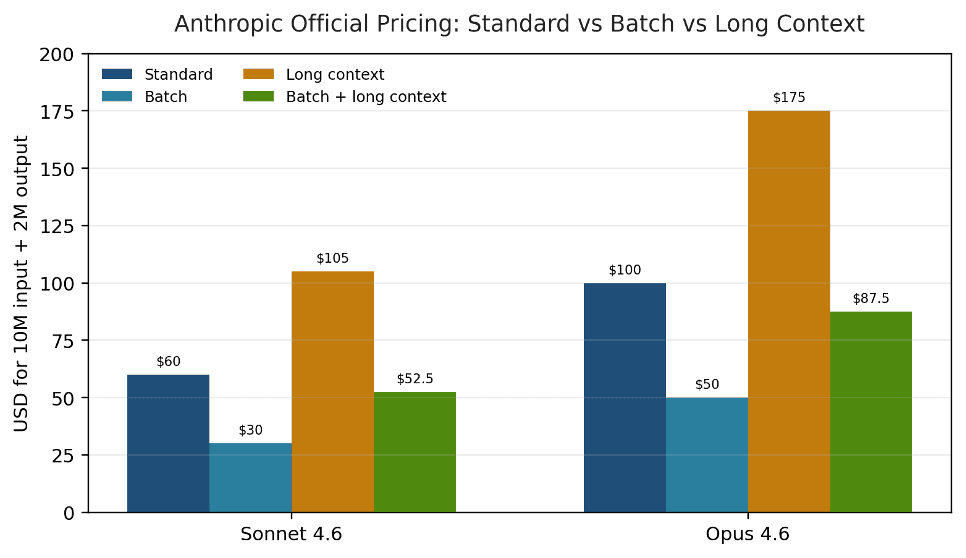
Figure 4. Long-context requests can raise effective cost sharply, but Batch still halves the bill when asynchronous execution is acceptable.
Pricing Tiers and Multipliers
Anthropic’s public 2026 pricing now has a cleaner ladder than many teams may assume from model names alone. Haiku 4.5 is the low-cost active tier, Sonnet 4.x is the middle band, and Opus 4.5 / 4.6 is the premium band. Above the base ladder, request modifiers matter: Batch halves price, caching changes input economics, long context raises rates on eligible requests, US-only inference adds a multiplier, and Opus 4.6 fast mode is a separate premium service.
| Feature | Public pricing rule | Stacks with | Cost-management implication |
|---|---|---|---|
| Batch processing | 50% discount on input and output tokens. | Prompt caching, long context, data residency | Best for asynchronous jobs such as offline summarization, extraction, and evaluation. |
| Prompt caching (5m) | Cache write = 1.25x base input; cache read = 0.1x base input. | Batch, long context, data residency | Best for repeated prompts that are reused quickly. |
| Prompt caching (1h) | Cache write = 2x base input; cache read = 0.1x base input. | Batch, long context, data residency | Useful when reuse happens over a longer window. |
| US-only inference | 1.1x multiplier on supported workloads. | Other token pricing categories listed by Anthropic | Relevant for data residency and compliance budgets. |
| Fast mode (Opus 4.6) | $30 / $150 per 1M tokens; 6x standard rates. | Prompt caching, data residency; not Batch | Reserve for latency-critical cases only. |
Source note: Official Anthropic pricing rules for Batch, prompt caching, data residency, and fast mode, checked on 2026-03-11.
When Pricing Multipliers Apply
- Batch is the cleanest savings lever for asynchronous work because it reduces both input and output by 50% without changing the model.
- Prompt caching changes input economics rather than output economics, which makes it especially valuable for large repeated system prompts or knowledge packs.
- Long-context pricing is triggered by request-level input tokens above 200K; it is not based on monthly aggregate usage.
- Fast mode should be treated as an explicit premium option for latency-sensitive work, not as a default runtime tier.
Batch Processing and Prompt Caching
Batch and caching are the two biggest publicly documented savings levers. Anthropic states that Batch reduces input and output charges by 50%, and that Batch discounts stack with prompt caching and long-context pricing. Prompt caching is especially attractive for repeated system prompts, knowledge bases, manuals, or code repositories. Anthropic’s documentation also gives simple break-even logic: a 5-minute cache write pays for itself after one cache read, while a 1-hour write pays for itself after two reads.
| Feature | Public pricing | Budget implication |
|---|---|---|
| Web search | $10 per 1,000 searches, plus standard token costs for search-generated content. | Track search counts separately from raw token spend. |
| Web fetch | No extra fee beyond standard token costs. | Useful when retrieval is needed but search billing is not justified. |
| Code execution | Free with web search or web fetch; otherwise 1,550 free hours per month, then $0.05/hour/container. 5-minute minimum. | Treat container hours as a separate operational meter. |
| Bash tool | Adds 245 input tokens per call. | Small per-call overhead, but relevant at very high volume. |
| Text editor tool (Claude 4.x) | Adds 700 input tokens per call. | Relevant when building coding and editing agents. |
Source note: Official Anthropic tool pricing and overheads, checked on 2026-03-11.
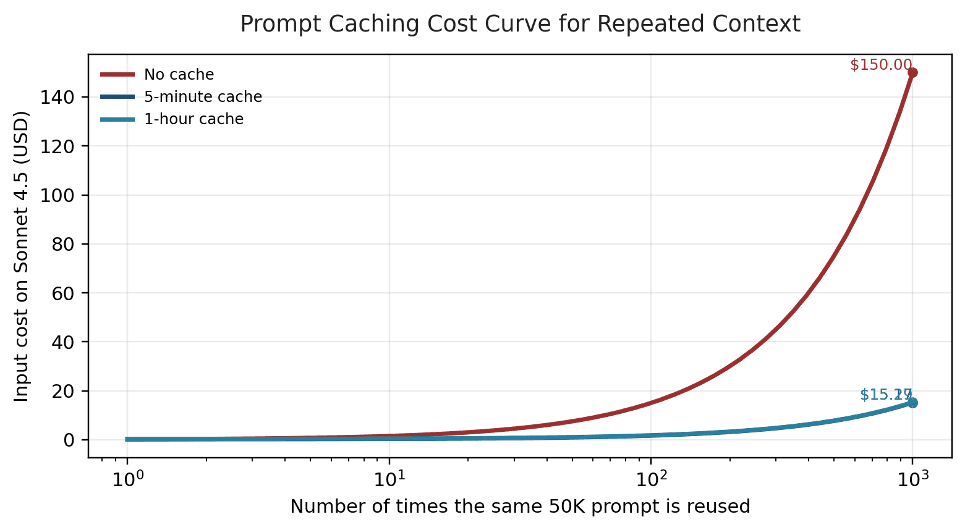
Figure 5. Repeated-context workloads become dramatically cheaper once Anthropic prompt caching is used.
Competitive Pricing Landscape in 2026
Comparison with Other API Providers
The major providers now publish more detailed rate cards than before, which makes vendor comparison possible but not perfectly apples-to-apples. Context thresholds, preview status, reasoning behavior, tool billing, and cached-token semantics differ across platforms. The table below therefore compares official list prices only.
| Provider | Model | Status | Input ($/1M) | Output ($/1M) | 10M in + 2M out | Note |
|---|---|---|---|---|---|---|
| Anthropic | Claude Haiku 4.5 | Active | $1.00 | $5.00 | $20.00 | Low-cost Anthropic tier |
| Anthropic | Claude Sonnet 4.6 | Active | $3.00 | $15.00 | $60.00 | Middle tier; 1M context available |
| Anthropic | Claude Opus 4.6 | Active | $5.00 | $25.00 | $100.00 | Premium Anthropic tier |
| OpenAI | GPT-5 mini | Active | $0.25 | $2.00 | $6.50 | Standard processing under 270K |
| OpenAI | GPT-5.4 | Active | $2.50 | $15.00 | $55.00 | Flagship model |
| Gemini 3.1 Flash-Lite Preview | Preview | $0.25 | $1.50 | $5.50 | Preview model | |
| Gemini 3.1 Pro Preview | Preview | $2.00 | $12.00 | $44.00 | Preview; ≤200K standard tier |
Source note: Anthropic pricing pages, OpenAI API pricing, and Google Gemini Developer API pricing, checked on 2026-03-11.
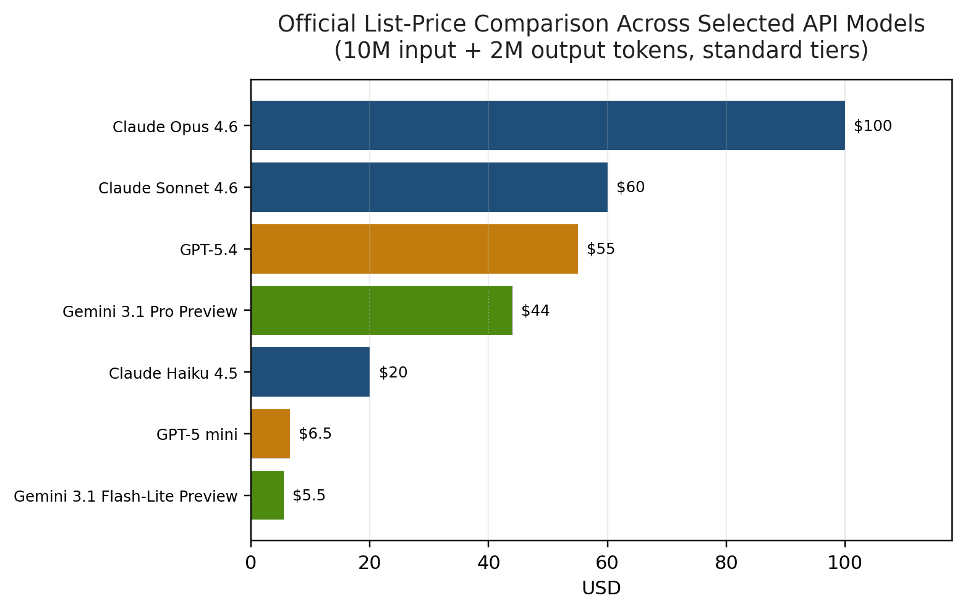
Figure 6. On raw list price, Anthropic’s public 2026 text-model tiers are not the cheapest in the market.
Strategic Positioning
At raw list price, Anthropic is not the cheapest public text API in 2026. Low-cost OpenAI and Google models undercut Haiku 4.5 on price, and Anthropic’s premium Opus tier sits above the flagship list prices shown on OpenAI and Google pages. Anthropic’s strongest pricing improvement is internal: premium users can now get a modern Opus tier at $5 / $25 instead of the older $15 / $75 baseline.
Subscription and Enterprise Pricing Plans
Anthropic now publishes its seat-plan structure more explicitly. Pro, Max, Team, and Enterprise are all publicly described, and self-serve Enterprise starts at $20 per seat with API usage billed separately. Anthropic also states that volume discounts may be available case by case for high-volume customers.
| Plan | Public price | What is billed separately | Best fit |
|---|---|---|---|
| Pro | $17/mo annual or $20/mo monthly | App usage only; API billing is separate | Individual productivity with Claude app features |
| Max | From $100/person/month | App usage only; API billing is separate | Heavy individual interactive use |
| Team Standard | $20/seat annual or $25/seat monthly | API billing is separate | Shared team workspace with admin features |
| Team Premium | $100/seat annual or $125/seat monthly | API billing is separate | Higher-usage team seats |
| Enterprise (self-serve) | $20/seat | Usage billed separately at API rates | Larger deployments needing spend controls and admin features |
Source note: Anthropic Claude plan pricing from claude.com/pricing, checked on 2026-03-11.
When to Choose Subscriptions Over API Pricing
Seat plans and API pricing serve different buying jobs. Pro, Max, Team, and Enterprise bundle product surfaces, memory, research, collaboration, connectors, and administration. API pricing is the right framework for embedded product features, backend agents, programmatic routing, and cost-per-call governance. Because Anthropic does not publish plan usage in token-equivalent quotas, breakeven should be judged by workflow fit and governance needs rather than by assuming one seat equals a fixed API token budget.
| Workload pattern | Suggested model | Why this follows from the pricing data |
|---|---|---|
| High-volume chatbot | Haiku 4.5 | Cheapest active observed option on the latest date; use-case tag = Chatbot. |
| Balanced coding and agents | Sonnet 4.5 or 4.6 | Middle-tier pricing; Sonnet 4.6 adds 1M context capability. |
| Long-context coding or document analysis | Sonnet 4.6 | 1M context family with lower token rates than Opus. |
| Premium long-context workflows | Opus 4.6 | Best reserved for measured quality lift because token cost is materially higher than Sonnet. |
| Legacy premium baseline | Avoid defaulting to Opus 4 / 4.1 | Still visible in the observed history, but far more expensive than Opus 4.5 / 4.6. |
Source note: Suggested model guidance combines the 2026 historical pricing series with Anthropic’s current public pricing structure.
Cost Optimization Strategies for Users
Budgeting and Cost Management
Budgeting should begin with three measurements: model family, output share, and the frequency with which requests cross 200K input tokens. In Anthropic’s public schedule, those three variables move spend more than almost anything else. Long prompts can double input rates; verbose outputs can dominate base cost; and a wrong default model family can create a 5x spread before any optimizations are applied.
Practical Budgeting Strategies
- Forecast input and output separately instead of relying on a single blended token estimate.
- Gate requests that cross 200K input tokens so long-context pricing is deliberate rather than accidental.
- Use Haiku or Sonnet as defaults and promote to Opus only where measured quality lift justifies the premium.
- Use Batch for non-urgent workloads such as offline evaluation, summarization, and document processing.
- Cache large static prompt blocks aggressively, especially knowledge bases and long system prompts.
- Track web search and stand-alone code execution separately from raw token spend.
Discounts and Cost Savings Opportunities
Anthropic’s discount logic is now explicit enough to model directly. On Sonnet 4.6, the same 10M / 2M workload costs $60 at standard rates, $30 in Batch, $105 at long-context rates, and $52.50 when long-context work is also batched. That is why architecture-level controls matter as much as base model selection.
Batch Processing Cost Example
For asynchronous classification, extraction, summarization, or offline evaluation pipelines, Batch is the cleanest savings lever because it cuts the bill in half without changing model quality. The trade-off is latency and operational complexity, not model behavior.
| Workload pricing basis | Input rate | Output rate | Cost for 10M in + 2M out |
|---|---|---|---|
| Sonnet 4.6 standard | $3.00 | $15.00 | $60.00 |
| Sonnet 4.6 Batch | $1.50 | $7.50 | $30.00 |
| Sonnet 4.6 long context | $6.00 | $22.50 | $105.00 |
| Sonnet 4.6 Batch + long context | $3.00 | $11.25 | $52.50 |
| Opus 4.6 standard | $5.00 | $25.00 | $100.00 |
| Opus 4.6 Batch | $2.50 | $12.50 | $50.00 |
| Opus 4.6 long context | $10.00 | $37.50 | $175.00 |
| Opus 4.6 Batch + long context | $5.00 | $18.75 | $87.50 |
Source note: Illustrative workload costs use official Anthropic 2026 rates for standard, Batch, and long-context pricing.
Prompt Caching Example
For repeated context, caching can be even more dramatic. A 50K prompt reused 1,000 times on Sonnet 4.5 costs $150 if re-sent on every call. The same input footprint costs about $15.17 with a 5-minute cache or about $15.29 with a 1-hour cache because most of the bill shifts from full input processing to low-cost cache reads. If the workload also qualifies for Batch, the 5-minute cached version falls to about $7.59.
| Case | Pricing logic | Input cost on repeated 50K context | Savings vs re-sending |
|---|---|---|---|
| No cache | 50M input tokens re-sent at $3.00 / 1M | $150.00 | — |
| 5-minute cache | 50K write at $3.75 / 1M + 49.95M reads at $0.30 / 1M | $15.17 | 89.9% |
| 1-hour cache | 50K write at $6.00 / 1M + 49.95M reads at $0.30 / 1M | $15.29 | 89.8% |
| 5-minute cache + Batch | Cached total × 0.5 | $7.59 | 94.9% |
Source note: Prompt-caching example uses Sonnet 4.5 public Anthropic pricing for a repeated 50K prompt across 1,000 calls.
Optimizing Your Architecture
The practical design pattern is straightforward: route the first pass to the cheapest viable family, promote only hard cases, keep static context cached, and use asynchronous queues for non-urgent work. High-cost paths should be opt-in, observable, and easy to audit.
Understanding Pricing Components and API Billing
Anthropic bills the API on actual usage, but 2026 pricing now includes enough modifiers that a single blended token estimate is no longer enough. Teams need per-request telemetry for input tokens, output tokens, cache reads and writes, and server-side tools.
Key Pricing Transparency Elements
- Base model-context prices were stable across the observed 69-day historical window.
- The long-context threshold is request-level input over 200K, not monthly volume.
- Batch and prompt caching stack; fast mode does not stack with Batch.
- Web search and stand-alone code execution can create non-token charges.
- Seat plans and API usage should be budgeted as separate commercial products.
Optimizing Context Window Strategy
The right question is not whether a model can reach 1M context, but how often production traffic actually needs to cross 200K input tokens. Many applications benefit from 1M-capable models while still paying standard rates most of the time. The cost problem emerges when large prompts become the default rather than the exception.
Pricing Trends and Competitive Dynamics
The early-2026 historical trend is portfolio refresh rather than ongoing repricing. Opus 4.6 appears on Feb. 7, Sonnet 4.6 on Feb. 18, Claude 3.5 Haiku and Claude 3.7 Sonnet disappear from the daily record on Feb. 19, and Claude 3 Haiku becomes deprecated on Mar. 2. Public Anthropic pricing reinforces the same pattern: differentiation is increasingly delivered through model tiering and feature modifiers rather than through constant headline rate changes.
| Date | Observed portfolio change |
|---|---|
| 2026-01-05 | Claude 3 Opus disappears from the observed daily history. |
| 2026-02-07 | Claude Opus 4.6 appears with 1M context; Claude 3.5 Haiku changes from active to deprecated. |
| 2026-02-18 | Claude Sonnet 4.6 appears with 1M context. |
| 2026-02-19 | Deprecated Claude 3.5 Haiku and Claude 3.7 Sonnet disappear from the daily history. |
| 2026-03-02 | Claude 3 Haiku becomes deprecated; Haiku 4.5 becomes the cheapest active observed option. |
Source note: Observed portfolio changes are drawn from the early-2026 Anthropic historical pricing series.
Enterprise Considerations and API Fees
Enterprise pricing now needs to account for more than token rates. Web search, code execution, data residency, and seat-plan administration each affect total cost of ownership. Anthropic’s self-serve Enterprise plan also separates seat price from API usage, which makes governance costs more visible than in a pure token-only view.
Cost Management by Organizational Scale
| Organizational scale | Suggested pricing posture | Primary cost variables |
|---|---|---|
| Startup / product team | Default to Haiku 4.5 or Sonnet 4.5/4.6. | Output share, Batch eligibility, and repeated-context caching. |
| Mid-market / multi-endpoint | Standardize routing and isolate premium exceptions. | Long-context threshold, web search charges, and code-execution hours. |
| Enterprise / compliance | Budget seats, API routing, and governance together. | US-only inference, spend controls, rate-limit needs, and case-by-case volume discounts. |
Source note: Guidance blends Anthropic public commercial terms with the observed early-2026 model and pricing history.
Make Informed Infrastructure Decisions
Token price tables are useful, but operational behavior determines the real bill. Model launches change the approved routing set, deprecations affect fallback behavior, and large-context features can shift the marginal cost of a single request. Teams should pin model IDs, log fallback events, review long-context traffic separately, and revisit budgets when new 4.x variants arrive or 3.x variants retire.
The availability timeline below shows why procurement and engineering should use the same pricing artifact. Base prices stayed steady in the historical record, but portfolio composition did not. A stable model budget still needs active lifecycle management.
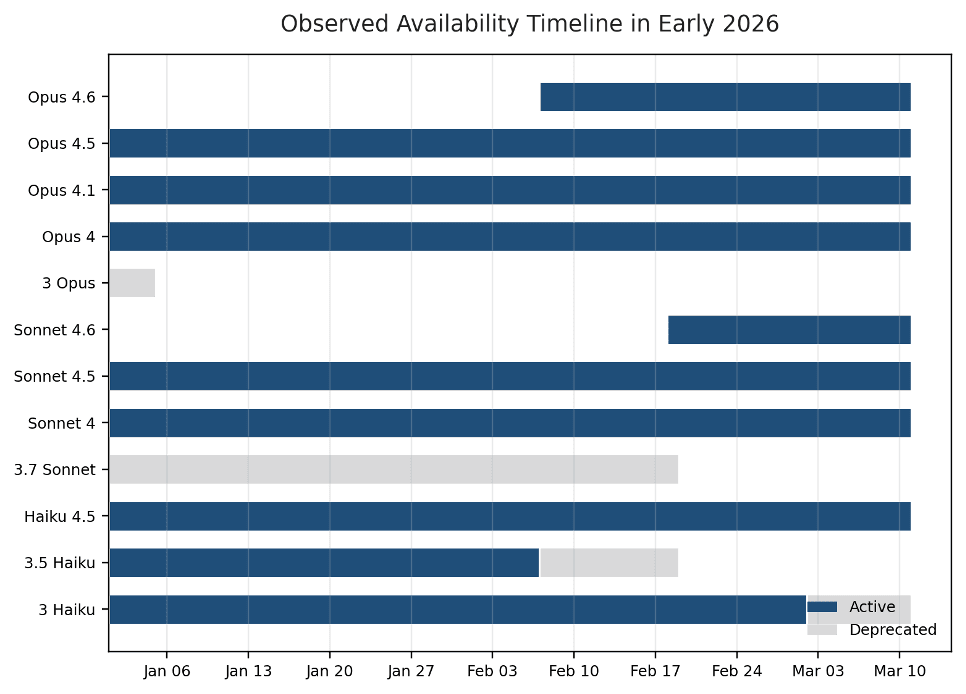
Figure 7. Early-2026 Anthropic pricing was stable at the base-rate level, but the observed model portfolio changed materially.
Conclusion and Strategic Recommendations
Summary of Key Insights
The 2026 Claude pricing picture is clearer and more commercially detailed than many high-level summaries suggest. The historical record shows stable base prices plus a cheaper modern premium tier; Anthropic’s public docs add the commercial mechanics around Batch, caching, long context, tools, and seat plans. The result is a pricing system that rewards routing discipline more than blanket premium-model usage.
Strategic Recommendations
- Default to Haiku 4.5 or Sonnet 4.5 / 4.6 unless measured lift justifies Opus.
- Treat 1M context as a governed capability, not as a default prompt size.
- Use Batch wherever latency is not user-visible and throughput matters more than immediacy.
- Cache large static prompt blocks aggressively, especially for repeated manuals, policies, or code context.
- Separate token, tool, and seat-plan budgets in reporting so true cost drivers are visible.
- Review approved model lists and pricing baselines whenever new 4.x variants land or 3.x variants retire.
Forward-Looking Perspective
If the first quarter of 2026 is a guide, Anthropic’s next pricing moves are more likely to come through portfolio evolution and feature-level commercialization than through abrupt base-rate cuts. Teams that already meter context size, routing behavior, and feature usage will be best positioned to absorb those changes without surprise.
Selected public sources: Anthropic pricing pages and developer pricing documentation; OpenAI API Pricing; Google Gemini API Pricing.